Top 10 Open-Source Big Data Tools in 2024
In the dynamic world of big data, open-source tools are pivotal in empowering organizations to harness the immense potential of vast and complex datasets. Moreover, as we enter 2024, the landscape big data tools and technologies continues evolving because it provides cutting-edge storage, processing, analysis, and data management solutions.
In this blog, we will look at the top ten open-source big data analytics tools of 2024 and explore the cutting-edge technologies that will power the future of data-driven decision-making.
These big data software tools are the backbone of modern data ecosystems, from real-time stream processing to distributed storage systems. Let"s dive into the tools shaping the big data landscape in 2024.
1. Apache Hadoop:
Apache Hadoop is the backbone of big data because it is considered a reliable and flexible framework that aids in storing and processing vast amounts of data across clusters of commodity hardware. It includes the Hadoop Distributed File System (HDFS) for storage, the MapReduce programming model for data processing, and YARN for resource management.
Key Features of Apache Hadoop:
- The latest version of Apache Hadoop is 3.3.6, released in 2023
- Authentication improvements when using HTTP proxy server
- The ideal features of Apache Hadoop include Fault Tolerance, Data Locality, Open Source, Rich Ecosystem, Programming Language Flexibility, Data Compression and Optimization, Security, Community Support, etc.
- Due to this exclusive feature support, Apache Hadoop is widely utilized by many industries like Technology and IT, Finance, Healthcare, Government, Media and Entertainment, Transportation and Logistics, etc.
- To operate Apache Hadoop effectively, you typically need programming language skills, particularly in languages like Java or Python, for writing MapReduce jobs, data processing scripts, and configuring Hadoop components.
- Many organizations across various industries use Hadoop for big data processing and analytics.
The well-known organizations include:
- Amazon
- Netflix
- IBM
- Microsoft
- Yahoo!
- NASA (National Aeronautics and Space Administration)
Due to this, Apache Hadoop is a prominent and widely used tool in big data processing and analytics.
2. Apache Spark:
This framework is considered a game-changer in big data analytics because it is well known for its swiftness and Multifacetedness, and Spark supports various data processing tasks.A fast and general-purpose cluster computing framework supports in-memory data processing, machine learning, and graph processing. Its in-memory computing capabilities speed up data processing and analysis.
The key feature of Apache Spark:
- The latest version of Apache Spark was Spark 3.1.2
- One unique feature of Apache Spark is its ability to perform in-memory data processing.
- Programming Model of Apache Spark is Resilient distributed Datasets (RDD)
- Spark can integrate with various data sources and storage systems, including Hadoop Distributed File System (HDFS), Apache Cassandra, Apache HBase, and more.
- Spark offers high-level APIs in various programming languages like Python, Java, Scala, and R, making it accessible to many developers.
- Apache Spark is a versatile big data processing framework that has found applications in various industries due to its ability to efficiently handle large-scale data processing and analytics.
Some of the industries that utilize Apache Spark include:
- Finance
- Healthcare
- E-commerce
- Manufacturing
- Media and Entertainment
- Government and Public Sector
- Research and Academia
- Many large and small organizations utilize Apache Spark for various data processing and analytics tasks.
Here are some notable organizations that have adopted Apache Spark:
- Netflix
- Amazon
- Uber
- IBM
- Adobe
3. Apache Kafka:
A distributed streaming platform is utilized for building real-time data pipelines and streamlining applications. It is one of the primary big data management tools. Its distributed architecture allows for Scalability, High Throughput, Fault Tolerance, Low Latency, Horizontal Scaling, Data Retention and Data Integration.
Key features of Apache Kafka
- The current stable version is 3.5.1
- Kafka 3.5.1 is considered a security patch release.
- It contains security fixes and regression fixes.
- Kafka 3.4.1 has fixed 58 issues since the 3.4.0 release.
- Kafka has a rich ecosystem of connectors and libraries that make integrating various data sources and sinks easy, including databases, data warehouses, and other streaming platforms.
- To work efficiently with Apache Kafka, you must understand Java, Scala, Distributed messaging system, and Linux environment.
Many organizations worldwide utilize Apache Kafka, including:
- Uber
- Netflix
- Cisco
Apache Kafka is widely utilized across various industries for real-time data streaming. The industries include:
- Finance
- Retail and E-commerce
- Healthcare
- Telecommunications
- Manufacturing
- Media and Entertainment, etc.
4. Elasticsearch:
It is one of the top big data analytics tools. Elasticsearch can also be used for big data analytics, especially when combined with the ELK (Elasticsearch, Logstash, and Kibana) stack. It is typically utilized for log and data analysis by providing flexible Search and Retrieval Capabilities across large datasets.
Key Features of Elasticsearch:
- The latest version is 8.10.0
- It has the capability of breaking changes, Bug fixation, Deprecations, and Enhancements.
- It has unique features such as Application, Data streams, Search, and security.
- It supports tokenization, stemming, relevance scoring, and faceted Search.
- Python, a scripting language that supports Elasticsearch
Many industries are utilizing Elasticsearch, and a few industries include:
- E-commerce
- Healthcare
- Finance
- Media and Entertainment
- Retail
- Technology
- Government
- Energy and Utilities
Top organizing utilizing Elasticsearch are:
- Netflix
- eBay
- Adobe
- Shopify
- Uber
- Slack Technologies
- The New York Times, NASA, etc.
5. Apache Flink:
Apache Flink is a stream processing framework for big data processing and analytics. It provides both batch and stream processing capabilities. It is well known for its Low Latency, High Throughput, Event Time Processing, Dynamic Scaling, Native Batch Processing,Compatibility, etc.
Key Features of Apache Flink:
- The latest stable release Apache Flink 1.17.1
- It introduces a new feature called "gateway mode.
- SQL Client/SQL Gateway provides new support for managing job lifecycles
Flink 1.17 introduced:
- Watermark Alignment Support
- Streaming FileSink Expansion
- RocksDBStateBackend Upgrade
- Calcite Upgrade
- PyFlink
- Daily Performance Benchmark
- Subtask Level Flame Graph
- To work with Apache Flink, Java, and Scala are mandatory programming languages.
- Industries that utilize Apache Flink include E-commerce, Media and Entertainment, Technology, Manufacturing, etc.
Organizations that utilize Apache Flink include:
- Netflix
- Uber
- Airbnb
- Lyft
- Zalando
- ING Bank
- Cisco
6. Apache Cassandra:
A highly scalable NoSQL database that provides high availability and partition tolerance. It"s designed for handling large amounts of data across distributed clusters. It is suitable for applications that require high write throughput and low-latency data access.
Key Features of Apache Cassandra:
Apache Cassandra 4.1 is the latest version. Pluggability is the primary theme of Apache Cassandra. Apache Cassandra ecosystem has features like Pluggable Memtable Implementation, SSL Context Creation, and Pluggable External Schema Manager Services.The essential skills you require to become a Cassandra developer include database knowledge, Object-Oriented Programming language, and NoSQL database. Apache Cassandra is widely used across various industries and by numerous organizations for its scalability and high availability.
Here, we shall look at some of the industries and organizations that use Apache Cassandra:
Industries:
• Technology• Finance• Retail• Telecommunications• Healthcare
Organization:
• Netflix• Apple• eBay• Facebook• Twitter• Instagram
7. TensorFlow:
TensorFlow offers a versatile platform for machine learning and deep learning tasks. It can scale from mobile devices to large clusters, making it suitable for various applications. The rich ecosystem of Tensorflow simplifies the development and deployment of AI applications.
Key Features of TensorFlow:
- The latest version of TensorFlow Release is 2.14.0
- The Tensorflow pip package has a new installation method for Linux
- We should have PySpark or Python programming language skills to work efficiently with TensorFlow.
- The Industries utilize TensorFlow, such as Technology, Healthcare, Finance, Media and Entertainment, Automotive, etc.
Organizations using TensorFlow technology, such as:
- Amazon
- Microsoft
- IBM
8. Apache NiFi:
Apache NiFi simplifies collecting, transferring, and routing data between systems, making it a powerful big data integration tools, streaming, and transformation. Its modular architecture allows for easy customization and scalability, adapting to the evolving needs of data processing pipelines and workflows.
Key Features of Apache NiFi:
- Apache NiFi Sources 1.23.2
- Apache NiFi has features like a Browser-based user interface, Data provenance tracking, Extensive configuration, Extensible design, and secure communication.
- It has a rich feature of loss-tolerant, low latency, and Dynamic prioritization.
- To work with NiFi, you should have a profound understanding of Java, Data ingestion, transformation, and ETL.
- Top industries that utilize Apache NiF include Technology, Healthcare, Finance, Government, Transportation and Logistics, etc.
- Many organizations have adopted Apache NiF, including the National Aeronautics and Space Administration, American Express, Goldman Sachs, Verizon, Ford, etc.
These are a few industries and organizations that utilize Apache NiF.
9. Presto:
Presto is an open-source distributed SQL query engine for querying large datasets federated across multiple data sources. It is a flexible tool for ad-hoc analysis because of its fast efficiency and capability for querying data in several formats.
Key features of Presto:
- Presto"s recent release is 0.283
- Fix Queued Query Count JMX Metrics and Improve Performance.
- Improve error handling and improve null inferencing for join nodes.
- To work with Presto technology, you should have a Distributed Query Engine, Multi-Source Querying, and Ecosystem Integration.
- Presto is used across a variety of industries and by many organizations. Some of the top industries and organizations that utilize Presto include:
Industries:
- Technology
- E-commerce
- Finance
- Media and Entertainment
- Healthcare
Organization:
- Netflix
- Uber
- Walmart
10. OpenRefine:
It is the best tool for big data analytics. OpenRefine is an effective tool for cleaning and transforming messy data, making it more consistent and usable for analysis. It provides an intuitive, user-friendly interface that allows users to interactively explore and refine their data without requiring advanced programming skills.
OpenRefine
- The new version of OpenRefine is 3.7.5
- OpenRefine"s UI can be translated, and new media files can be uploaded to Wikibase instances such as Wikimedia Commons.
- OpenRefine supports undo and redo functionality and can be used on Windows, macOS, and
- Linux operating systems.
- No prior knowledge or skills are required.
- There are many industries and organization that utilizes OpenRefine.
Some of them include:
Organization:
- Wikimedia Foundation
- The New York Times
- ProPublica
- Stanford University
- The World Bank
Industries:
- Education
- Media and Publishing
- Nonprofit and Research
- Government and Public Services
- Technology
Now that you have understood, the top 10 open-source big data tools and techniques help shape the future of data-driven decision-making. From the details above, you would have understood the features of Big data tools and the skills required to work efficiently with these tools. Moreover, you comprehensively understood organizations and industries utilizing Big Data tools according to their business needs.
Staying current with the latest developments in the big data ecosystem is crucial to harnessing the full potential of these tools and maintaining a competitive edge in tomorrow"s data-driven world.
Find a course provider to learn Big Data
Java training | J2EE training | J2EE Jboss training | Apache JMeter trainingTake the next step towards your professional goals in Big Data
Don't hesitate to talk with our course advisor right now
Receive a call
Contact NowMake a call
+1-732-338-7323Take our FREE Skill Assessment Test to discover your strengths and earn a certificate upon completion.
Enroll for the next batch
big data full course
- Jun 22 2026
- Online
big data full course
- Jun 23 2026
- Online
big data full course
- Jun 24 2026
- Online
big data full course
- Jun 25 2026
- Online
big data full course
- Jun 26 2026
- Online
Related blogs on Big Data to learn more

What is Big Data – Characteristics, Types, Benefits & Examples
Explore the intricacies of "What is Big Data – Characteristics, Types, Benefits & Examples" as we dissect its defining features, various types, and the tangible advantages it brings through real-world illustrations.


AWS Big Data Certification Dumps Questions to Practice Exam Preparation
Certification in Amazon Web Service Certified Big data specialist will endorse your skills in the design and implementation of the AWS services on the data set. These aws big data exam questions are prepared as study guide to test your knowledge and

Top 25 Big Data Questions and Answers for Certification Passing score
You can appear for big data certification exam with confidence and come out with certification. We have prepared a bunch of important big data exam questions along with the correct answer and the explanation for the right answer. Utilize these sample

Sixth Edition of Big Data Day LA 2018 - Register Now!
If you’re keen tapping into the advances in the data world, and currently on a quest in search engines, looking for Big Data conferences and events in the USA, there is a big one coming up your way! Yes, the sixth annual edition of Big Data Day LA
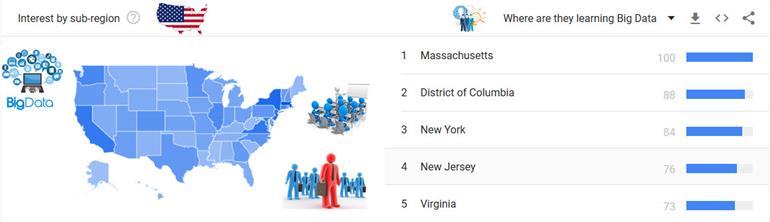
15 Popular Big Data Courses to learn for the future career
We have found a list of big data courses that are necessarily required for the future. Professionals and freshmen who are learning these courses prepare the participants to see bigdata careers with high pay jobs.

Best countries to work for Big Data enthusiasts
China is fast becoming a global leader in the world of Big Data, and the recently held China International Big Data Industry Expo 2018

Top Institutes to enroll for Big Data Certification Courses in NYC
If achieving a career breakthrough is hard, harder is sustaining a long-run. Why? Organizations are focusing on New Yorkers who can work dynamically and leverage their skills from the word go, and that’s why.

The emergence of Cloudera
Cloudera is the leading worldwide platform provider of Machine Learning. There is reportedly an accelerated momentum in the Cybersecurity market.

Why there is a need to fill the skill gap to land in a Hadoop and Big Data career?
The world is witnessing the tremendous learning of Big Data platform and artificial intelligence associated with it. The demand for Analytics skill is going up steadily but there is a huge deficit on the supply side.
Latest blogs on technology to explore

Drug Safety & Pharmacovigilance: Your 2026 Career Passport to a Booming Healthcare Industry!
Why This Course Is the Hottest Ticket for Science Grads & Healthcare Pros (No Lab Coat Required!)" The Exploding Demand for Drug Safety Experts "Did you know? The global pharmacovigilance market is set to hit $12.5B by 2026 (Grand View Research, 202

Launch Your Tech Career: Why Mastering AWS Foundation is Your Golden Ticket in 2026
There’s one skill that can open all those doors — Amazon Web Services (AWS) Foundation

Data Science in 2026: The Hottest Skill of the Decade (And How Sulekha IT Services Helps You Master It!)
Data Science: The Career that’s everywhere—and Nowhere Near Slowing Down "From Netflix recommendations to self-driving cars, data science is the secret sauce behind the tech you use every day. And here’s the kicker: The U.S. alone will have 11.5 mill

Salesforce Admin in 2026: The Career Goldmine You Didn’t Know You Needed (And How to Break In!)
The Salesforce Boom: Why Admins Are in Crazy Demand "Did you know? Salesforce is the 1 CRM platform worldwide, used by 150,000+ companies—including giants like Amazon, Coca-Cola, and Spotify (Salesforce, 2025). And here’s the kicker: Every single one

Python Power: Why 2026 Belongs to Coders Who Think in Python
If the past decade was about learning to code, the next one is about coding smarter. And in 2026, the smartest move for any IT enthusiast is learning Python — the language that powers AI models, automates the web, and drives data decisions across ind

The Tableau Revolution of 2025
"In a world drowning in data, companies aren’t just looking for analysts—they’re hunting for storytellers who can turn numbers into decisions. Enter Tableau, the #1 data visualization tool used by 86% of Fortune 500 companies (Tableau, 2024). Whether

From Student to AI Pro: What Does Prompt Engineering Entail and How Do You Start?
Explore the growing field of prompt engineering, a vital skill for AI enthusiasts. Learn how to craft optimized prompts for tools like ChatGPT and Gemini, and discover the career opportunities and skills needed to succeed in this fast-evolving indust

How Security Classification Guides Strengthen Data Protection in Modern Cybersecurity
A Security Classification Guide (SCG) defines data protection standards, ensuring sensitive information is handled securely across all levels. By outlining confidentiality, access controls, and declassification procedures, SCGs strengthen cybersecuri

Artificial Intelligence – A Growing Field of Study for Modern Learners
Artificial Intelligence is becoming a top study choice due to high job demand and future scope. This blog explains key subjects, career opportunities, and a simple AI study roadmap to help beginners start learning and build a strong career in the AI

Java in 2026: Why This ‘Old’ Language Is Still Your Golden Ticket to a Tech Career (And Where to Learn It!
Think Java is old news? Think again! 90% of Fortune 500 companies (yes, including Google, Amazon, and Netflix) run on Java (Oracle, 2025). From Android apps to banking systems, Java is the backbone of tech—and Sulekha IT Services is your fast track t