Learn the Tools and Techniques for Effective Data Processing in Big Data Analytics

Data processing: Data processing is the process of transforming the raw data into meaningful information to provide insights. To process large volume of data (big data), a set of programming models are applied to access the large-scale data to extract meaningful insights. Big data is stored in several commodity servers. Hence, traditional models like MPI(Message passing interface) do not suffice.
What makes big data processing effective?
Big data processing has few requirements to be effective. Based on the characteristics, big data requirements can be classified as:
Volume: Volume in big data refers to the enormous amount of data that overwhelms organizations. Today’s businesses are bombarded with data from various sources like social media/networks, transaction processing mechanisms, and many more. The traditional local server storage does not suffice the requirement. Therefore, big data tools and techniques help to split the colossal volume of data into chunks and save across several clusters of servers. We will understand more about such tools and techniques in the later part of this article.
Velocity: The term velocity in big data refers to the speed with which the data is generated, captured, and processed. A few decades ago, it took a while for the data to get processed and to share the right information. But in today’s digital era, real-time data is available which has to be processed with greatest speed. Big data tools and technologies help to monitor and process the enormous data in real-time and help business leaders to take informed, data-driven decisions in a timely manner.
Variety: Variety in big data refers to the digitized data that an organization gets and sends in various formats. It can be structured or unstructured data. It is important to track and interpret this variety of data. This is where the big data tools and technologies come in place. We will understand more about such tools and techniques in the later part of this article.
Veracity: The term Veracity in big data refers to the quality of data and the accuracy of data. Validation of Small quantity of data is simple and to check for he accuracy and quality is also easy. Unfortunately, large volumes of data is tough to validate and check for accuracy and quality. By the time the data is validated, it may become obsolete. Therefore, big data tools and technologies help in accuracy and maintaining quality of the data. Such data is a boon as it can help to predict consumer preferences and can prevent diseases to many more wonders.
Open source tools and technologies in Big Data processing
Apache Hadoop: Apache Hadoop is a Java-based open-source framework that is used to store and process very large data. The data sets may vary from giga bytes to petabytes. The unique feature of Hadoop is that it enables numerous analytical tasks to run on the same data set. The framework distributes the big data and the analytics across several nodes in clusters and then breaks down into smaller chunks which can be run parallelly. Hadoop has flexible features which allow the storage of structured and unstructured data in any format.
Apache Cassandra: Apache Cassandra is an open-source, NoSQL database which is most suitable for high-speed and online transactional data. This amazing tool can manage enormous amounts of data across commodity servers. The best aspect is that Cassandra provides high availability with no failure point and allows low latency operations for clients. The data distribution across multiple data centers is made easy with replication.
Apache Storm: The Apache storm is an open source distributed real-time computation system and can be used with any programming language. This tool is fault tolerant and has horizontal scalability. Apache storm is a single node processing system and can process the data even when the node is disconnected.
Apache Spark: Apache Spark works on in-memory cluster computing technology. This open-source tool speeds up the processing speed of an application. Apache Spark works on batch applications, interactive queries, iterative algorithms and many more workloads. Spark supports several/multiple languages and provides built-in APIs for Java, Scala, and Python. Apart from supporting Map and Reduce, Spark supports data streaming, SQL queries, machine learning and algorithms.
MongoDB: MongoDB is popular in agile teams. A Mongo database is a non-relational document database that supports huge data storage in a structured manner without disturbing the stack. All the documents can be stored in a schema-less database.
Qubole: Qubole is a big data tool that uses machine learning, and artificial intelligence, and can adapt to a multi-cloud system. Multi-source data can be migrated to a single location with Qubole. This amazing tool aids in predictive analysis. Qubole also provides real-time insights into moving data pipelines. This reduces the time and effort.
Apache Hive: Apache Hive is a distributed data-warehousing system. This amazing tool facilitates analytics from the central data warehouse. The analytics function I performed at a large scale on petabytes of data residing in the distributed storage.
KNIME: Konstanz Information Miner (KNIME) is an open-source platform that supports Linux and Windows operating systems. This open-source big data tool is useful for enterprise reporting, data mining, data analytics and text mining.
High-Performance Computing Cluster (HPCC): High-Performance Computing Cluster (HPCC) is an open-source tool that offers a 369-degree big data solution. This is also called a data analytics supercomputer which is based on Thor architecture. It’s a hugely scalable supercomputing platform.
Integrate.io: Integrate.io is an excellent big data tool that can perform big data analytics on a cloud platform. This amazing scalable cloud platform can function without code or low code capability. This big data cloud platform has a capacity to connect to more than 150 data sources. This is one of the efficient ETL and data transformation tool.
Factors to be considered before selecting the appropriate big data tool:
- Business objectives
- Cost
- Advanced analytics
- Usage and ease of use
- Security
Conclusion: There are several tool which are available in the business world. You should learn and understand the tool that is widely used by businesses. Every tool had its own Pros and cons. You should also understand the type of business that business are using and the purpose of analysis. Happy learning.
Find a course provider to learn Big Data
Java training | J2EE training | J2EE Jboss training | Apache JMeter trainingTake the next step towards your professional goals in Big Data
Don't hesitate to talk with our course advisor right now
Receive a call
Contact NowMake a call
+1-732-338-7323Take our FREE Skill Assessment Test to discover your strengths and earn a certificate upon completion.
Enroll for the next batch
big data full course
- Jun 22 2026
- Online
big data full course
- Jun 23 2026
- Online
big data full course
- Jun 24 2026
- Online
big data full course
- Jun 25 2026
- Online
big data full course
- Jun 26 2026
- Online
Related blogs on Big Data to learn more

What is Big Data – Characteristics, Types, Benefits & Examples
Explore the intricacies of "What is Big Data – Characteristics, Types, Benefits & Examples" as we dissect its defining features, various types, and the tangible advantages it brings through real-world illustrations.
Top 10 Open-Source Big Data Tools in 2024
In the dynamic world of big data, open-source tools are pivotal in empowering organizations to harness the immense potential of vast and complex datasets. Moreover, as we enter 2024, the landscape big data tools and technologies continues evolving be

AWS Big Data Certification Dumps Questions to Practice Exam Preparation
Certification in Amazon Web Service Certified Big data specialist will endorse your skills in the design and implementation of the AWS services on the data set. These aws big data exam questions are prepared as study guide to test your knowledge and

Top 25 Big Data Questions and Answers for Certification Passing score
You can appear for big data certification exam with confidence and come out with certification. We have prepared a bunch of important big data exam questions along with the correct answer and the explanation for the right answer. Utilize these sample

Sixth Edition of Big Data Day LA 2018 - Register Now!
If you’re keen tapping into the advances in the data world, and currently on a quest in search engines, looking for Big Data conferences and events in the USA, there is a big one coming up your way! Yes, the sixth annual edition of Big Data Day LA
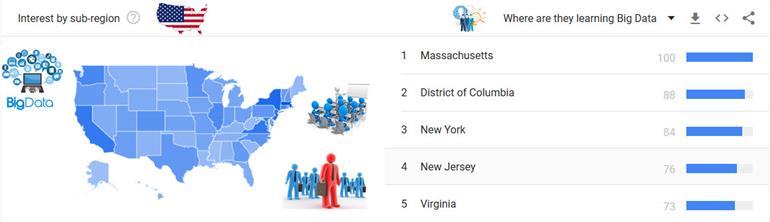
15 Popular Big Data Courses to learn for the future career
We have found a list of big data courses that are necessarily required for the future. Professionals and freshmen who are learning these courses prepare the participants to see bigdata careers with high pay jobs.

Best countries to work for Big Data enthusiasts
China is fast becoming a global leader in the world of Big Data, and the recently held China International Big Data Industry Expo 2018

Top Institutes to enroll for Big Data Certification Courses in NYC
If achieving a career breakthrough is hard, harder is sustaining a long-run. Why? Organizations are focusing on New Yorkers who can work dynamically and leverage their skills from the word go, and that’s why.

The emergence of Cloudera
Cloudera is the leading worldwide platform provider of Machine Learning. There is reportedly an accelerated momentum in the Cybersecurity market.

Why there is a need to fill the skill gap to land in a Hadoop and Big Data career?
The world is witnessing the tremendous learning of Big Data platform and artificial intelligence associated with it. The demand for Analytics skill is going up steadily but there is a huge deficit on the supply side.
Latest blogs on technology to explore

Drug Safety & Pharmacovigilance: Your 2026 Career Passport to a Booming Healthcare Industry!
Why This Course Is the Hottest Ticket for Science Grads & Healthcare Pros (No Lab Coat Required!)" The Exploding Demand for Drug Safety Experts "Did you know? The global pharmacovigilance market is set to hit $12.5B by 2026 (Grand View Research, 202

Launch Your Tech Career: Why Mastering AWS Foundation is Your Golden Ticket in 2026
There’s one skill that can open all those doors — Amazon Web Services (AWS) Foundation

Data Science in 2026: The Hottest Skill of the Decade (And How Sulekha IT Services Helps You Master It!)
Data Science: The Career that’s everywhere—and Nowhere Near Slowing Down "From Netflix recommendations to self-driving cars, data science is the secret sauce behind the tech you use every day. And here’s the kicker: The U.S. alone will have 11.5 mill

Salesforce Admin in 2026: The Career Goldmine You Didn’t Know You Needed (And How to Break In!)
The Salesforce Boom: Why Admins Are in Crazy Demand "Did you know? Salesforce is the 1 CRM platform worldwide, used by 150,000+ companies—including giants like Amazon, Coca-Cola, and Spotify (Salesforce, 2025). And here’s the kicker: Every single one

Python Power: Why 2026 Belongs to Coders Who Think in Python
If the past decade was about learning to code, the next one is about coding smarter. And in 2026, the smartest move for any IT enthusiast is learning Python — the language that powers AI models, automates the web, and drives data decisions across ind

The Tableau Revolution of 2025
"In a world drowning in data, companies aren’t just looking for analysts—they’re hunting for storytellers who can turn numbers into decisions. Enter Tableau, the #1 data visualization tool used by 86% of Fortune 500 companies (Tableau, 2024). Whether

From Student to AI Pro: What Does Prompt Engineering Entail and How Do You Start?
Explore the growing field of prompt engineering, a vital skill for AI enthusiasts. Learn how to craft optimized prompts for tools like ChatGPT and Gemini, and discover the career opportunities and skills needed to succeed in this fast-evolving indust

How Security Classification Guides Strengthen Data Protection in Modern Cybersecurity
A Security Classification Guide (SCG) defines data protection standards, ensuring sensitive information is handled securely across all levels. By outlining confidentiality, access controls, and declassification procedures, SCGs strengthen cybersecuri

Artificial Intelligence – A Growing Field of Study for Modern Learners
Artificial Intelligence is becoming a top study choice due to high job demand and future scope. This blog explains key subjects, career opportunities, and a simple AI study roadmap to help beginners start learning and build a strong career in the AI

Java in 2026: Why This ‘Old’ Language Is Still Your Golden Ticket to a Tech Career (And Where to Learn It!
Think Java is old news? Think again! 90% of Fortune 500 companies (yes, including Google, Amazon, and Netflix) run on Java (Oracle, 2025). From Android apps to banking systems, Java is the backbone of tech—and Sulekha IT Services is your fast track t