Breaking down Hadoop in layman terms
Hadoop! This strangely sounding term is bound to spring up every now and then if you are reading or doing some research on Big Data analytics. So, what is Hadoop? What does Hadoop do and why is it needed? Read on to delve into the fine details of Hadoop.
In simple terms, Hadoop is a collection of open source programs/procedures relating to Big Data analysis. Being open source, it is freely available for use, reuse and modification (with some restrictions) for anyone who is interested in it. Big Data scientists call Hadoop the ‘backbone’ of their operations. In fact, Hadoop certification has become the next stepping stone for experienced software professionals who are starting to feel stagnated in their current stream.
The birth of Hadoop
As it had always been with the IT industry, it was the innovation of a bunch of forward thinking software engineers at Apache Software Foundation that led to the introduction of Hadoop. These engineers realized that reading data from bulk storage devices took longer than reading it from small storage devices of multiple numbers working simultaneously. Moreover, eliminating one single large storage location also made data available to multiple users spread across a network.
The first version of ApacheTM Hadoop framework was released in 2005 and ever since it paved the way for better Big Data Analytics. Internationally, Hadoop courses are in hot demand since they offer the promise of a lucrative career in a domain, i.e. Big Data, which is going to grow with leaps and bounds.

Trivia: Hadoop is named after the toy elephant belonging to the son of one of the key developers.
The 4 ‘Modules’ of Hadoop and what they stand for
Hadoop comprises mainly of 4 modules namely, DFS, MapReduce, YARN and Hadoop Common. Each of these module has a specific task assigned to it for facilitating Big Data Analytics.
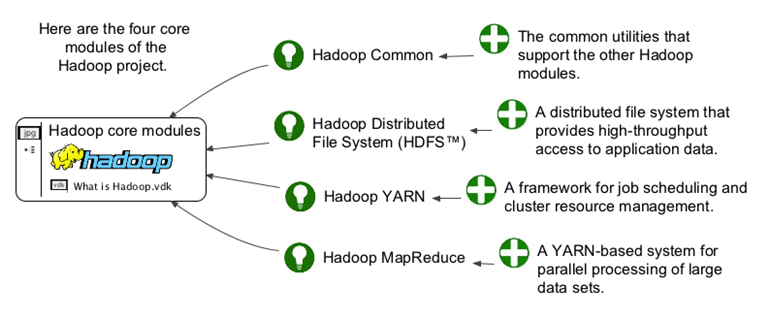
1. Hadoop Common
Hadoop Common provides Java-based user tools that are to be used for accessing and retrieving data stored in a Hadoop file system.
2. Distributed File System (DFS)
In Hadoop, Distributed File System is what enables data to be stored in a form that can be easily accessed and retrieved. The data will be stored across several interconnected devices which can be reached for using MapReduce.
3. YARN
The fourth and final module, YARN manages the system resources when the analytics are being conducted on the data stored in linked devices.
4. MapReduce
MapReduce basically does two primary functions: it reads data from databases and puts them into a format that is suitable for Big Data Analytics. Further, it breaks down the data into meaningful information that can be used for interpretation. For instance, how many male members above the age of 30 in a given data population.
Over the period of years a good number of other features have also come to form essential part of the Hadoop framework. However, the above-mentioned four modules continue to be the main elements that denote the Hadoop architecture. Hadoop training courses also assert more impetus on these four core elements as the framework is deemed to be updated revolving them.
How Hadoop favors the Fortune companies
Hadoop is meant for Big Data analytics. Hence, its primary users are corporations that have massive chunks of data awaiting analysis and interpretation across multiple geographical locations. Needless to say, at least 90% of the Fortune 500 Companies have integrated Hadoop tutorials and training program for their engineers to make better use of Big Data.
The International Data Corporation’s “Trends in Enterprise Hadoop Deployments” report states that at least 32% of the enterprises have actually deployed Hadoop and another 36% preparing to deploy it within the next one year. Another similar report by Gartner, Inc. also forecasted 30% of enterprises to have already invested heavily in Hadoop infrastructure.
Four reasons why corporations will continue sticking on to Hadoop:
- It is flexible. More data systems can be added, edited or deleted when required.
- It is cost-effective and practical. More storage units can be added by procuring readily-available storage from IT vendors.
- It is open source, providing ample flexibility for corporations to customize it the way they want for effective use. Unlike bespoke off-shelf software systems that are rigid and complex to customize.
- Commercial versions like Cloudera are available in the market which further simplify the process of installing and setting up the Hadoop framework.
In a nutshell
Hadoop in a nutshell (a large one, that is) is an open-source, flexible and robust framework for Big Data Analytics. It is made up of 4 major modules and more are being added to it for diverse applications. Apache presented Hadoop to the world in 2005. There is a thriving community of Hadoop developers and users where anything and everything related to the framework can be asked for and discussed. Find it here.
Find a course provider to learn Hadoop
Java training | J2EE training | J2EE Jboss training | Apache JMeter trainingTake the next step towards your professional goals in Hadoop
Don't hesitate to talk with our course advisor right now
Receive a call
Contact NowMake a call
+1-732-338-7323Take our FREE Skill Assessment Test to discover your strengths and earn a certificate upon completion.
Enroll for the next batch
Hadoop Hands-on Training with Job Placement
- Jun 1 2026
- Online
Hadoop Hands-on Training with Job Placement
- Jun 2 2026
- Online
Hadoop Hands-on Training with Job Placement
- Jun 3 2026
- Online
Hadoop Hands-on Training with Job Placement
- Jun 4 2026
- Online
Hadoop Hands-on Training with Job Placement
- Jun 5 2026
- Online
Related blogs on Hadoop to learn more

Hadoop Big Data Analytics Market Share, Size, and Forecast to 2030
In an era driven by data, the Hadoop Big Data Analytics market stands at the forefront of innovation and transformation. The landscape is poised for exponential growth and evolution as we peer into the future. The "Hadoop Big Data Analytics Market Sh

Hadoop Certification Dumps with Exam Questions and Answers
We have collated some Hadoop certification dumps to make your preparation easy for the Hadoop exam. The questions are multiple-choice patters and we have also highlighted the answer in bold. A brief description of the answer is also mentioned for eas

Apache Hadoop 3.1.2, the brand new software to help
The recent update of Apache Hadoop 3.1.2 had the changes software engineers always intended in the Apache Hadoop- 2. Version. This version includes improvements and additional features from the previous Apache Hadoop, This version is available (GA) a

Learning Hadoop would enhance your Big Data career!
Big Data was among the most sought after careers which are louder and deeper in recent years. Though there are many different interpretations of big data, the need to manage huge clusters of unstructured data matter in the end. Big data simply refers

Top 4 Reasons to enroll for Hadoop Training!
#4 Top Companies around the world into Hadoop Technology World's top leading companies such as DELL, IBM, AWS (Amazon Web Services), Hortonworks, MAPR Technologies, DATASTAX, Cloudera, SUPERMICR, Datameer, adapt, Zettaset, Pentaho, KARMASPHERE and m

Important Components in Apache Hadoop Stack
Apache HDFS Apache HDFS is one of the core significant technologies of Apache Hadoop which acted as a driving force for the next level elevation of Big Data industry. This cost-effective technology to process huge volumes of data revolutionized the

Apache Hadoop Essential Training Course
Learn the Fundamentals of Apache Hadoop Introduction to Apache Hadoop: This introductory class describes the students to learn the basics of Apache Hadoop. This course is a short and sweet preface to the point of Hadoop Distributed File System and

Hadoop simply dominates the big data industry!
Anyone in the data science market must have witnessed the enormous growth and popularity of Hadoop in such a short time. How Hadoop made such a drastic dominance in the big data mainstream? Let us examine the maturity of it in this blog.

Top 5 differences between Apache Hadoop and Spark
"Explore the key distinctions between Apache Hadoop and Spark in this comprehensive comparison, highlighting their unique features and applications in big data processing."

Hadoop developer among the most paid professionals
It turns out that Hadoop developers are among the top paid professionals across the world. Below is the list of most paid professions where Hadoop skills occupy most of them. MapReduce is worth $127,315
Latest blogs on technology to explore

Drug Safety & Pharmacovigilance: Your 2026 Career Passport to a Booming Healthcare Industry!
Why This Course Is the Hottest Ticket for Science Grads & Healthcare Pros (No Lab Coat Required!)" The Exploding Demand for Drug Safety Experts "Did you know? The global pharmacovigilance market is set to hit $12.5B by 2026 (Grand View Research, 202

Launch Your Tech Career: Why Mastering AWS Foundation is Your Golden Ticket in 2026
There’s one skill that can open all those doors — Amazon Web Services (AWS) Foundation

Data Science in 2026: The Hottest Skill of the Decade (And How Sulekha IT Services Helps You Master It!)
Data Science: The Career that’s everywhere—and Nowhere Near Slowing Down "From Netflix recommendations to self-driving cars, data science is the secret sauce behind the tech you use every day. And here’s the kicker: The U.S. alone will have 11.5 mill

Salesforce Admin in 2026: The Career Goldmine You Didn’t Know You Needed (And How to Break In!)
The Salesforce Boom: Why Admins Are in Crazy Demand "Did you know? Salesforce is the 1 CRM platform worldwide, used by 150,000+ companies—including giants like Amazon, Coca-Cola, and Spotify (Salesforce, 2025). And here’s the kicker: Every single one

Python Power: Why 2026 Belongs to Coders Who Think in Python
If the past decade was about learning to code, the next one is about coding smarter. And in 2026, the smartest move for any IT enthusiast is learning Python — the language that powers AI models, automates the web, and drives data decisions across ind

The Tableau Revolution of 2025
"In a world drowning in data, companies aren’t just looking for analysts—they’re hunting for storytellers who can turn numbers into decisions. Enter Tableau, the #1 data visualization tool used by 86% of Fortune 500 companies (Tableau, 2024). Whether

From Student to AI Pro: What Does Prompt Engineering Entail and How Do You Start?
Explore the growing field of prompt engineering, a vital skill for AI enthusiasts. Learn how to craft optimized prompts for tools like ChatGPT and Gemini, and discover the career opportunities and skills needed to succeed in this fast-evolving indust

How Security Classification Guides Strengthen Data Protection in Modern Cybersecurity
A Security Classification Guide (SCG) defines data protection standards, ensuring sensitive information is handled securely across all levels. By outlining confidentiality, access controls, and declassification procedures, SCGs strengthen cybersecuri

Artificial Intelligence – A Growing Field of Study for Modern Learners
Artificial Intelligence is becoming a top study choice due to high job demand and future scope. This blog explains key subjects, career opportunities, and a simple AI study roadmap to help beginners start learning and build a strong career in the AI

Java in 2026: Why This ‘Old’ Language Is Still Your Golden Ticket to a Tech Career (And Where to Learn It!
Think Java is old news? Think again! 90% of Fortune 500 companies (yes, including Google, Amazon, and Netflix) run on Java (Oracle, 2025). From Android apps to banking systems, Java is the backbone of tech—and Sulekha IT Services is your fast track t