MapReduce and Elasticsearch guide for consultants and end-users
Need of MapReduce and Elasticsearch
Big Data processing is one of the primary concern for the enterprises today because the data sets are increasing day by day and its analysis is one of the most difficult tasks performed by the data analytics. Big data is the data sets which are so voluminous and complicated, that the traditional data processing techniques won"t be able to manage and that gives rise to the need for alternative processing techniques. Further such big data sets do not only involve the data scale and volume, but it includes some other essentials aspects too such as the data velocity, data variety, data volume and its complexity.
For instances, the data generated at Instagrams, WhatsApp, YouTube, Facebook needs to be managed on a daily basis and the data collected at these platforms are falls under the category of big data.
The chart below depicts the traditional approach with its comparison with the big data analyses approach as we have discussed above:
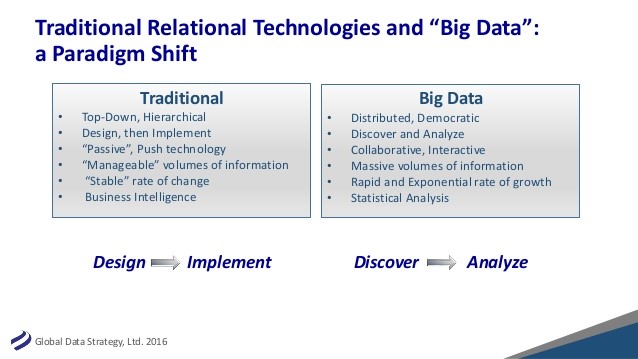
Introduction:
The advanced programs/models developed to solve the problems of analyzing the big data sets are:
MapReduce – It is a programming model which helps in writing the applications which can be able to process the big data as it provides the analytical capabilities for interpreting the huge and complex data structure. MapReduce is a data-parallel programming model which is pioneered by Google for clustering the systems. It is executed for preparing and producing extensive datasets to tackle an assortment of real-world situations and issues.
The calculation conducted in this modeling involves terms like:
-a map function
-a reduce function, and
-the underlying runtime framework
It further consequently parallelizes the computation of the handling machine or system failures, effective and efficient use of the networks and disks, scheduling the inter-system communication
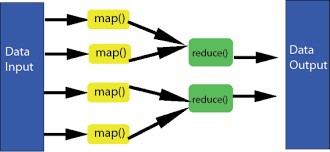
MapReduce model works by dividing the tasks into the small parts and then assigning them to the various other systems. In the end, the outputs are composed at a single place which integrates to form the resulted dataset.
Therefore, the image represents the MapReduce model as:
Elastic search- It is an amazing tool for indexing and conducting the full text search. It is a real-time distributed and also having an open-source full-text search and analytics engine.
The engine uses a Domain Specific query Language which is based on JSON and is also very simple to understand and access but at the same time is also very powerful also.
Some notable features of the elastic search tool are as:
-It is an open source.
-It is broadly-distributable,
-It is readily-scalable,
-It is one of the standardized enterprise-grade search engines,
-It is easily accessible through a considerable and intricate API.
Elastic search module is considered as one of the most popular enterprise search engines which are being used by some big corporates such as The Guardian, Wikipedia, GitHub, StackOverflow and etc.
As explained above, we have provided with a representation of an elastic search model for your better understanding:
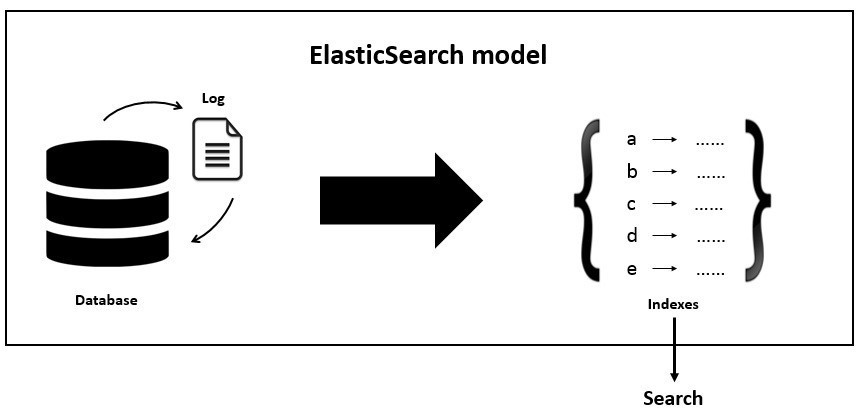
Advantages:
First, we will discuss some of the advantageous of MapReduce model such as:
The MapReduce model is quite simple to work upon but is also very expressive at the same time. The model does not need to have the specification of the physical attributes of the tasks across the nodes. The model is independent as doesn’t have any dependency on the data model and the schema. The model can work with both types of data such as structured and unstructured. The model can also work upon the different storage layers as Big Table and many more. The model offers highly fault tolerance where the tasks on failed nodes will have to be restarted, and the model also achieves the high scalability with the block level scheduling.
The advantages of the elastic search are as:
It is scalable up to the petabytes of data’s such as structured and unstructured data. It can also be used as a replacement of document stores such as MongoDB and RavenDB. It also makes use of the denormalization which helps in improving the search performance. The model is developed in Java, which supports in the making is well compatible with acts on every platform. The model acts as a real-time, as in layman language if we state that every new document added after a second and so is available for the search in this advanced engine. It is also distributable which helps in making it easy to scale and integrate into the big corporates. It also provides full backups, handles the multi-tenancy, and uses the JSON objects as responses. Elasticsearch supports all types of documents except those that do not support the text rendering.
How does the MapReduce model work?
The MapReduce is the model which contains on the two main tasks named as map and reduce.
The graphical representation of the MapReduce programming model is to provide you a better understanding:
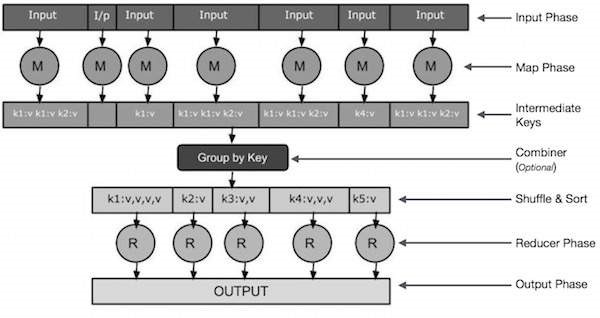
Map tasks:
Where the Map task involves the set of data and converts it into the different sets of data, where the single elements are further broken down into the tuples which are known as key-value pairs. It involves the below steps as:
• Input Phase step denotes − the Record Reader which will translate every record in an input file and helps in sending the parsed data to the mapper in the key-value pairs forms.
• Map phase step denotes – It is a phase of function which is defined by the user, it takes a key-value pair’s series and further processes each pair of series to generate zero or more key-value pairs.
• Intermediate Keys denotes – the key-value pairs created on the map phase are known as intermediate keys.
• Combiner denotes− it is an optional function as it is not a part of the MapReduce model, it is a type of local reducer which helps in grouping the same kind of data into the identifiable data sets.
Reduce tasks:
Where in the Reduce task takes the output form the map task and that works as an input for this task and further combines the data key-value pairs into the small set of tuples. It involves the below steps as:
• Shuffle and Sort denote – the reduce tasks will start from the Shuffle and Sort step. It helps in downloading the grouped key-value pairs which are taken from the map tasks onto the local system, where the reducer function is running. Here the single key-value pairs are sorted by the key into the more extensive data list.
• Reducer denotes − The Reducer phase takes the grouped key-value paired data as input and then runs a reducer function on each of the clustered pairs.
• Output Phase – This the last step of the model where the output value is found. Here the output format translates the final key-value pairs received from the reducer function and further writes them into the file by using a record writer.
The Elasticsearch model:
The graphical representation of the elastic search is to provide you a better understanding:
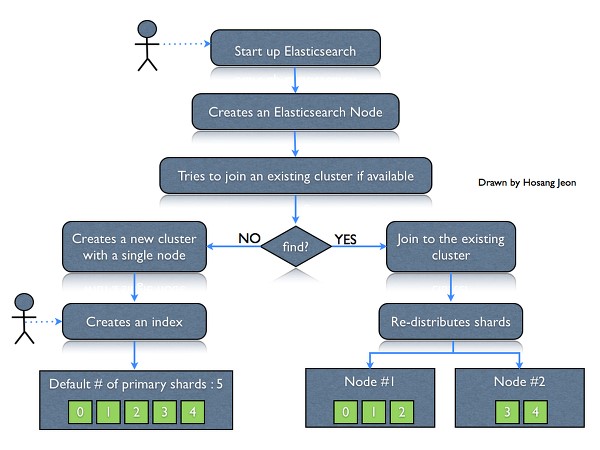
The concepts involved in the above Elastic search representation and their descriptions are as follows:
- Node – It refers to a single running occurrence of the Elasticsearch. Single physical and virtual server obliges various nodes relying on the capacities of their tangible assets like RAM, stockpiling and handling power.
- Cluster − It is a gathering of one or more than one nodes. Group gives aggregate indexing and search abilities over every one of the nodes for the whole data set.
- Index − It is a gathering of various kind of documents and its properties. Indexes additionally utilize the concepts of shard to enhance the performance...
- Mapping /type− it is an accumulation of records sharing an arrangement of standard fields shows in similar indexes. For instance, an Index contains information of social networking apps, and afterward, there can be a particular kind of client profile data, another type for the messages data and another for remarks data
- Document − It is an accumulation of fields in a specific way characterized in JSON format. Each and every document belongs to a particular type and resides into an index, and further, each and every document file is further related to a unique identifier which is known as the UID.
- Shard − It is the indexes which are horizontally diversified into the shards. This implies every shard contains every one of the properties of the document, however, contains less number of JSON objects than an index file. The horizontal partition makes shard an autonomous node, which can further be stored in any node. The primary shard is the original part of an index file, and then also these primary shards are replicated into the replica shards.
- Replicas - Elasticsearch enables its users to create replicas of their records (indexes) and shards. Replication not just aides in expanding the accessibility of data in the case of machine failure but it also helps in enhancing the performance of the searching by completing a parallel search task in such replications.
This is the ready reference guide for the professionals who all aspire to learn the basics of Big Data Analytics using the MapReduce programming model and the Elasticsearch model with its involved concepts in a simple and transparent manner. It is a useful guide for the consultants as well as for the end-users.
Take the next step towards your professional goals in MapReduce
Don't hesitate to talk with our course advisor right now
Receive a call
Contact NowMake a call
+1-732-338-7323Related blogs on MapReduce to learn more

MapR Converged Data Platform for Beginners
Run through the MapR Converged Data Platform Fundamental Introduction to MapR Converged Data Platform: This introductory class describes the basics of MapR Converged Data Platform. The attendee will gain an essential knowledge and skills to work.
Latest blogs on technology to explore

Drug Safety & Pharmacovigilance: Your 2026 Career Passport to a Booming Healthcare Industry!
Why This Course Is the Hottest Ticket for Science Grads & Healthcare Pros (No Lab Coat Required!)" The Exploding Demand for Drug Safety Experts "Did you know? The global pharmacovigilance market is set to hit $12.5B by 2026 (Grand View Research, 202

Launch Your Tech Career: Why Mastering AWS Foundation is Your Golden Ticket in 2026
There’s one skill that can open all those doors — Amazon Web Services (AWS) Foundation

Data Science in 2026: The Hottest Skill of the Decade (And How Sulekha IT Services Helps You Master It!)
Data Science: The Career that’s everywhere—and Nowhere Near Slowing Down "From Netflix recommendations to self-driving cars, data science is the secret sauce behind the tech you use every day. And here’s the kicker: The U.S. alone will have 11.5 mill

Salesforce Admin in 2026: The Career Goldmine You Didn’t Know You Needed (And How to Break In!)
The Salesforce Boom: Why Admins Are in Crazy Demand "Did you know? Salesforce is the 1 CRM platform worldwide, used by 150,000+ companies—including giants like Amazon, Coca-Cola, and Spotify (Salesforce, 2025). And here’s the kicker: Every single one

Python Power: Why 2026 Belongs to Coders Who Think in Python
If the past decade was about learning to code, the next one is about coding smarter. And in 2026, the smartest move for any IT enthusiast is learning Python — the language that powers AI models, automates the web, and drives data decisions across ind

The Tableau Revolution of 2025
"In a world drowning in data, companies aren’t just looking for analysts—they’re hunting for storytellers who can turn numbers into decisions. Enter Tableau, the #1 data visualization tool used by 86% of Fortune 500 companies (Tableau, 2024). Whether

From Student to AI Pro: What Does Prompt Engineering Entail and How Do You Start?
Explore the growing field of prompt engineering, a vital skill for AI enthusiasts. Learn how to craft optimized prompts for tools like ChatGPT and Gemini, and discover the career opportunities and skills needed to succeed in this fast-evolving indust

How Security Classification Guides Strengthen Data Protection in Modern Cybersecurity
A Security Classification Guide (SCG) defines data protection standards, ensuring sensitive information is handled securely across all levels. By outlining confidentiality, access controls, and declassification procedures, SCGs strengthen cybersecuri

Artificial Intelligence – A Growing Field of Study for Modern Learners
Artificial Intelligence is becoming a top study choice due to high job demand and future scope. This blog explains key subjects, career opportunities, and a simple AI study roadmap to help beginners start learning and build a strong career in the AI

Java in 2026: Why This ‘Old’ Language Is Still Your Golden Ticket to a Tech Career (And Where to Learn It!
Think Java is old news? Think again! 90% of Fortune 500 companies (yes, including Google, Amazon, and Netflix) run on Java (Oracle, 2025). From Android apps to banking systems, Java is the backbone of tech—and Sulekha IT Services is your fast track t